Goutam BhatI am a fourth year PhD student at the Computer Vision Lab in ETH Zurich, under the supervision of Prof. Luc Van Gool. I am also advised by Dr. Martin Danelljan. My main research interests are Computer Vision and its applications, especially in the tasks of multi-frame image restoration, visual object tracking and segmentation. I received my M.Sc. degree in Computer Science from Linköping University, Sweden in 2019. I also worked as a research assistant at the Computer Vision Lab, Linköping University, from 2016-2018. Prior to that, I completed my B.Tech in Electrical Engineering at IIT Bombay, India in 2016. Email / GitHub / Google Scholar / |

|
Selected Publications |
|
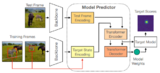
Transforming Model Prediction for TrackingChristoph Mayer, Martin Danelljan, Goutam Bhat, Matthieu Paul, Danda Pani Paudel, Fisher Yu, Luc Van Gool CVPR, 2022 arxiv / We propose a tracking architecture employing a Transformer-based model prediction module. Transformers capture global relations with little inductive bias, allowing it to learn the prediction of more powerful target models. We further extend the model predictor to estimate a second set of weights that are applied for accurate bounding box regression. The resulting tracker relies on training and on test frame information in order to predict all weights transductively. |
|
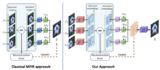
Deep Reparametrization of Multi-Frame Super-Resolution and DenoisingGoutam Bhat, Martin Danelljan, Fisher Yu, Luc Van Gool, Radu Timofte ICCV, 2021 (Oral Presentation) arxiv / code / We propose a deep reparametrization of the maximum a posteriori formulation commonly employed in multi-frame image restoration tasks. Our approach is derived by introducing a learned error metric and a latent representation of the target image, which transforms the MAP objective to a deep feature space. The deep reparametrization allows us to directly model the image formation process in the latent space, and to integrate learned image priors into the prediction. Our approach thereby leverages the advantages of deep learning, while also benefiting from the principled multi-frame fusion provided by the classical MAP formulation. |
|
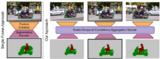
Generating Masks from Boxes by Mining Spatio-Temporal Consistencies in VideosBin Zhao, Goutam Bhat, Martin Danelljan, Luc Van Gool, Radu Timofte ICCV, 2021 arxiv / We introduce a method for generating segmentation masks from per-frame bounding box annotations in videos. To this end, we propose a spatio-temporal aggregation module that effectively mines consistencies in the object and background appearance across multiple frames. We use our resulting accurate masks for weakly supervised training of video object segmentation (VOS) networks. We generate segmentation masks for large scale tracking datasets, using only their bounding box annotations. The additional data provides substantially better generalization performance leading to state-of-the-art results in both the VOS and more challenging tracking domain. |
|
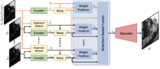
Deep Burst Super-ResolutionGoutam Bhat, Martin Danelljan, Luc Van Gool, Radu Timofte CVPR, 2021 arxiv / code / We propose a novel architecture for the burst super-resolution task. Our network takes multiple noisy RAW images as input, and generates a denoised, super-resolved RGB image as output. This is achieved by explicitly aligning deep embeddings of the input frames using pixel-wise optical flow. The information from all frames are then adaptively merged using an attention-based fusion module. In order to enable training and evaluation on real-world data, we additionally introduce the BurstSR dataset, consisting of smartphone bursts and high-resolution DSLR ground-truth. |

|
Learning What to Learn for Video Object SegmentationGoutam Bhat*, Felix Järemo Lawin*, Martin Danelljan, Andreas Robinson, Michael Felsberg, Luc Van Gool, Radu Timofte ECCV, 2020 (Oral Presentation) arxiv / code / We introduce an end-to-end trainable video object segmentation architecture that integrates a differentiable few-shot learning module to segment the taget object. We further go beyond standard few-shot learning techniques by learning what the few-shot learner should learn, in order to maximize segmentation accuracy. Our approach sets a new state-ofthe-art on the large-scale YouTube-VOS 2018 dataset. |

|
Know Your Surroundings: Exploiting Scene Information for Object TrackingGoutam Bhat, Martin Danelljan, Luc Van Gool, Radu Timofte ECCV, 2020 arxiv / code / We propose a novel tracking architecture which can exploit the knowledge about the presence and locations of other objects in the surrounding scene to prevent tracking failure. Our tracker represents such information as dense localized state vectors. These state vectors are propagated through the sequence by computing a dense correspondence and combined with the appearance model output to localize the target. |
|
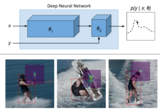
Energy-Based Models for Deep Probabilistic RegressionFredrik K. Gustafsson, Martin Danelljan, Goutam Bhat, Thomas B. Schön ECCV, 2020 arxiv / code / We propose a general and conceptually simple regression method with a clear probabilistic interpretation. We create an energy-based model of the conditional target density p(y|x), using a deep neural network to predict the un-normalized density from (x, y). This model of p(y|x) is trained by directly minimizing the associated negative log-likelihood, approximated using Monte Carlo sampling. |

|
Learning Discriminative Model Prediction for TrackingGoutam Bhat*, Martin Danelljan*, Luc Van Gool, Radu Timofte ICCV, 2019 (Oral Presentation) arxiv / code / We propose an end-to-end trainable tracking architecture, capable of fully exploiting both target and background appearance information for learning the target model. Our architecture is derived from a discriminative learning loss by designing a dedicated optimization process. The proposed tracker sets a new state-of-the-art on 6 tracking benchmarks, while running at over 40 FPS. |

|
ATOM: Accurate Tracking by Overlap MaximizationMartin Danelljan*, Goutam Bhat*, Fahad Shahbaz Khan, Michael Felsberg CVPR, 2019 (Oral Presentation) arxiv / code / We address the problem of estimating accurate bounding box in generic object tracking. We train a target estimation component offline to predict the overlap between the target object and an estimated bounding box, conditioned on the initial target appearance. We further introduce a target classification component that is trained online to guarantee high discriminative power in the presence of distractors. |
|
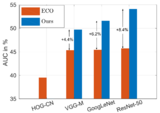
Unveiling the Power of Deep TrackingGoutam Bhat, Joakim Johnander, Martin Danelljan, Fahad Shahbaz Khan, Michael Felsberg ECCV, 2018 arxiv / We investigate the causes behind the limited success of using deep features for tracking. We identify the limited data and low spatial resolution of deep features as the main challenges, and propose strategies to counter these issues. Furthermore, we propose a novel adaptive fusion approach that leverages the complementary properties of deep and shallow features to improve both robustness and accuracy. |

|
ECO: Efficient Convolution Operators for TrackingMartin Danelljan, Goutam Bhat, Fahad Shahbaz Khan, Michael Felsberg CVPR, 2017 arxiv / code / We tackle the key causes behind the problems of computational complexity and over-fitting in advanced DCF trackers. We introduce: (i) a factorized convolution operator, which drastically reduces the number of model parameters; (ii) a compact generative model of the training sample distribution; (iii) a conservative model update strategy. Our approach can operate at 60 Hz on a single CPU, while obtaining competitive tracking performance. |
|
Design and source code from Jon Barron's website and Leonid Keselman's Jeckyll fork. |